楊浩藝,陳 微,姚澤歡,譚郁松,李 非
(1.國防科技大學計算機學院,湖南 長沙 410073;
2.中國科學院計算機網絡信息中心,北京 100190)
以侵襲性真菌感染為代表的感染性疾病是導致發病率高和死亡率高的重要原因,尤其對于艾滋病毒感染患者以及患有其他共病的免疫力低下的患者造成了重大威脅。這些真菌造成的死亡率與耐藥結核分岐桿菌造成的死亡率相當,超過了瘧疾[1]。當前已知的對人類有致病性的真菌多達300多種,根據抗真菌藥物的作用機制[2],已用于臨床的抗真菌藥物大致可分為多烯類、三唑類、烯丙胺類、棘白菌素和其他抗真菌藥物。然而人類真菌感染的病理生理學研究仍然遠落后于其他病原體引起的疾病[3]。此外,耐藥菌的出現和廣泛分布使得曾經容易治愈的疾病變得再次致命[4],以念珠菌為例,其對許多國家選擇的標準抗真菌藥物氟康唑以及新推出的棘孢菌素均具有耐藥性[5]。因此,安全有效的抗真菌藥物的研發顯得十分必要且迫切。
本文利用CMAP(Connectivity MAP)[6]和LINCS(Library of Integrated Network-based Cellular Signatures)[7]高通量轉錄組學數據,基于WTCS(WeighTed Connectivity Score)算法[8],從已有抗真菌藥物出發,發現其他藥物潛在的抗真菌用途。本文通過將生物大數據應用于快速藥物設計發現,基于生物醫藥數據特征構建端到端的藥物預測策略,為加快新的抗真菌藥物的研發進程提供計算方法。
根據Eroom定律[9],新藥研發成本持續增長。面對從無到有的漫長傳統藥物研發過程,迅速積累的生物醫學高通量數據推動了以生物信息學醫藥大數據為基礎的系統性藥物重定位[10]的發展,并引起研究人員廣泛關注。藥物重定位[11]針對已知的藥物識別和發現其新用途、新療效,是快速發現潛在藥物的不錯選擇,既能夠高效地找到目標藥物,也可提前預知藥物的副作用及用藥注意事項。以抗真菌藥物為例,在現有的、合成的或半合成的化合物庫中進行抗真菌活性篩選,能夠提前確定這些篩選出的化合物的最低毒性[1]。
數據驅動的藥物發現方法依賴高質量的數據資源,GenBank數據庫[12]整合了來自所有可用公共來源的DNA序列;
PharmGKB數據庫[13]為藥物研發提供了潛在的藥物-基因組關聯信息以及基因型-表型信息;
CMAP和LINCS數據庫[6]提供了在不同細胞系中加入多種化合物所產生的基因表達譜;
Drug Bank數據庫[14]作為一個獨特的生物信息學和化學信息學資源,結合了詳細的藥物/化學數據以及藥物靶標/蛋白質信息;
蛋白質結構數據庫PDB(Protein Data Bank)[15]提供了目前最完整的蛋白質三維結構數據。
無論是傳統的藥物發現流程還是藥物重定位,其關鍵點在于確定化合物的作用模式MOA(Mode Of Action)及其非靶點效應[16]。基于細胞轉錄反應檢測藥物作用模式(MOA)進而發現藥物的方法所需信息量最少,且可以快速應用于新的化合物[11]。轉錄組數據能夠直觀反映在某一特定條件下基因表達、基因過表達或者基因沉默的情況,不同條件下轉錄組數據結果不盡相同[17]。針對藥物發現來說,一是可以通過比較各種化合物作用于細胞與正常條件下細胞的轉錄組數據差異,找到有效藥物;
二是可以通過比較不同化合物在相同條件下作用于細胞的轉錄組數據,找到具有相同作用模式的化合物,進而達到發現潛在治療藥物的目的。在此背景下,利用基因表達譜、轉錄組譜以及生成的關聯網絡進行相關比對分析的方法以其快速高效、低成本的優勢在臨床治療、藥物作用模式闡述、藥物重定位和系統生物學等多個研究領域得到了應用和發展[12]。
Lamb等[6]創建了大型的藥物和基因標簽公共數據庫CMAP和LINCS,使得通過多種模式匹配算法挖掘生物數據特征之間的關聯性成為可能[18]。他們采用L1000技術[19]基于大規模的統計分析辨識出人類細胞中978個基因作為全基因組的標志基因,進一步通過計算預測獲得全部基因的表達量[20],實現了低成本、高通量的實驗數據獲取。到目前為止,LINCS計劃已獲得了77種典型細胞中的4 000多個沉默基因和7 000余種化學小分子刺激下的130余萬個全基因組表達譜[21],為構建不同藥物反應之間的關聯關系奠定了牢固的數據基礎。
本文針對抗真菌藥物進行藥物預測發現,以5種抗真菌分子化合物(氟胞嘧啶(flucytosine)、酮康唑(ketoconazole)、咪康唑(miconazole)、兩性霉素B(amphotericin B)和制霉菌素(nystatin))為基礎,基于CMAP數據庫對5種藥物與基因表達譜的聯通性分數排序,針對每種藥物確定一組上調和下調基因,每組包括10個基因。運用WTCS算法將查詢藥物的上、下調基因集與CMAP參考數據庫中的擾動分子進行富集分析,計算相似性分數并對其進行排序,得到每種目標藥物的相似藥物列表。
考慮到選取的是不同種藥物作用機制下的代表性藥物,作用機制不同使得基因差異表達情況不同,綜合分析5種抗真菌的藥物特點及其相似藥物列表結果之后,本文選擇合并多個相似藥物列表,利用RankAggreg[22]中的交叉熵-蒙特卡洛算法,分別采用Spearman footrule distance和Kendall’s tau distance 2種距離函數對5種相似藥物列表進行聚合,對比2種距離函數得到的聚合結果篩選出抗真菌藥物的預測藥物列表。
3.1 DPA藥物預測分析
基于Subramanian等[19]提出的WTCS計算相似性分數方法,本文提出藥物預測分析DPA(Drug Prediction Analysis)方法,如圖1所示。首先,通過CMAP數據庫找到目標藥物所對應的上、下調基因集,經過嘗試與計算,將每組上、下調基因集中的基因標簽數量控制在10個;
其次,通過計算目標藥物與CMAP參考標簽數據庫中每一個分子化合物擾動的相似性分數和差異顯著性值,將得到的藥物列表按照相似性分數由高到低進行排序,從而得到目標藥物的相似藥物列表;
最后,采用RankAggreg中的2種距離函數方法對5種抗真菌藥物的相似藥物列表進行聚合,得到最可能的抗真菌藥物預測結果。為了驗證該方法的正確性,本文利用Glaser等[23]公布的HDAC(Histone Deacetylase)抑制劑的基因表達標簽,對所設計的藥物預測方法進行正確性驗證。

Figure 1 DPA drug discovery analysis process圖1 DPA藥物發現分析流程
3.2 WTCS相似性計算
經典的基因集富集分析GSEA(Gene Set Enrichment Analysis)[21]方法以查詢目標化合物分子的基因標簽作為輸入,可以評估其與數據集中每個參考表達譜的相似性。給定所需要查詢計算的目標化合物分子的基因標簽(上調基因、下調基因),將目標化合物分子的基因標簽與CMAP數據庫中的編目列表進行比較分析,根據上調基因、下調基因在排序列表中的分布情況,可以將目標化合物的基因標簽與數據庫中的基因標簽的關系分為正相關、負相關和無關3種。而正、負相關又可細分為強正(負)相關和弱正(負)相關。比對后可以得到目標化合物分子基因標簽與數據庫中化合物分子基因標簽的聯通性分數(Connectivity Score),相似性分數的取值在-1~1。
WTCS算法對傳統的GSEA富集分析方法進行了改進,通過計算不同化合物分子基因標簽的富集分數得到不同化合物的聯通性分數,并通過聯通性分數的高低找到與目標藥物作用相似的藥物,進而達到重定位藥物的目的。該算法原理相對簡單,易于操作實現,在尋找相似化合物分子計算中已有廣泛的應用。
WTCS算法基于Kolmogorov-Smirnov富集統計ES(Enrichment Score)的非參數性相似性度量,對于輸入基因集(qup,qdown),按照式(1)的計算方式得到與某一參考基因標簽的相似性分數Wq,r:

(1)
其中,ESup、ESdown分別是qup、qdown在參考基因標簽下的富集分數。
3.3 Rank aggregation加權聚合排序
Rank aggregation是一種對多個排序列表進行整合得到一個綜合排序列表的算法[22]。在該算法中,Spearman footrule distance距離函數根據不同排序列表內元素的排序位置進行距離計算,該方法簡單且所需信息量少;
而Kendall’s tau distance距離函數需要聯合不同排序列表中對應的元素對距離進行綜合計算,該方法復雜但最終得到的結果列表排序等級差異明顯。Rank aggregation算法在R語言中有現成的包RankAggreg可用,因此實驗過程中只需要直接輸入需要聚合的排序列表,并調整迭代次數、距離函數等參數信息,使得結果收斂到最小。
4.1 數據和方法
首先利用R語言下載CMAP數據集,該數據集中包含多種化合物作用下不同細胞系細胞的基因表達譜。這些化合物可以是蛋白、小分子化合物或者是復雜化合物。通過查詢氟胞嘧啶、酮康唑、咪康唑、兩性霉素 B和制霉菌素的ID號,可以確定在這些化合物作用下細胞的基因表達情況,根據不同基因表達結果的排序篩選得到5種化合物的基因標簽集。本文的藥物相似性計算在整個CMAP數據集上針對所有化合物進行相似性計算分析。GSEA和WTCS算法的計算流程由Bioconductor[24]中的piano包(使用各種統計方法從不同的基因統計水平和廣泛的基因集合進行基因集分析)實現,通過分別對上調基因和下調基因進行富集分析,可以得到所要查詢的基因標簽與參考數據庫中的基因標簽的聯通性分數,以及差異顯著性值(P值)。藥物發現分析流程利用基于R語言實現的Bioconductor開源環境下的PharmacoGx[25]、piano、bioMaRt[26]和RankAggreg[22]等R語言包實現。
4.2 藥物相似性分析結果
在針對5種抗真菌藥物分別計算得到的排名前10的相似藥物列表結果(表1)中,酮康唑和咪康唑的相似藥物列表結果相似程度較高,酮康唑相似藥物列表中相似性分數最高的可達0.82,而咪康唑相似藥物列表中相似性分數最高可達0.88,這2種藥物的相似藥物列表在后續的實驗中值得關注;
與酮康唑和咪康唑的相似藥物列表相比,其余3種藥物的相似藥物結果相似程度相對較低,但前10位最相似藥物的相似性分數均在0.6以上。從實驗結果的準確性上看,上述藥物計算結果中,酮康唑和咪康唑的相似藥物結果不僅在相似性分數上表現較好,其結果的P值也幾乎全在0.01以內;
而兩性霉素B、制霉菌素和氟胞嘧啶的計算結果雖然在相似性分數和差異顯著性值上表現相對較差,大部分計算結果的P值均大于0.01,但除去極個別藥物外,這些相似藥物結果的P值均小于0.05,仍然具有一定的參考價值。5種目標藥物計算得到的P值結果如表2所示。從這些相似藥物結果也可以看出,由于不同的藥物作用機制不同,不同藥物的相似藥物以及其相似程度也存在明顯差異。

Table 1 List of inferred antifungal candidates表1 預測抗真菌候選藥物列表

Table 2 P-value list of inferred antifungal candidates表2 預測抗真菌候選藥物P值列表
4.3 抗真菌藥物預測結果
在5種藥物的相似藥物結果的基礎上,本文利用RankAggreg中的交叉熵-蒙特卡洛算法,分別采用Spearman footrule distance和Kendall’s tau distance 2種距離函數對5種藥物的相似藥物列表結果進行聚合排序。在4.2節得到的相似藥物排序結果中,根據化合物分子與目標藥物的正負相關性最終得到的相似性分數存在0~1,0,-1~0這3種情況。由于本實驗中只考慮正相關的情況,對于每種藥物的相似藥物列表只選擇相似性分數大于或等于0的化合物分子進行聚合排序,在實驗過程中不斷調整迭代次數、分位數和生成樣本數量等參數以獲得更加精確的收斂結果。由于計算方法的差異,采用Spearman footrule distance距離函數和Kendall’s tau distance距離函數最終收斂得到的結果數值水平存在一定差異(如圖2所示),但利用2種距離函數聚合得到的藥物列表排序結果相似。通過排除掉5種目標查詢藥物,最終選擇了10種化合物分子作為抗真菌藥物預測藥物結果(如表3所示),分別是伊利替康(irinotecan)、氯硝柳胺(niclosamide)、舍他康唑(sertaconazole)、普尼拉明(prenylamine)、銀杏內酯A(ginkgolide A)、莫索尼啶(moxonidine)、槲皮素(quercetin)、舒洛地爾(suloctidil)、卡米達佐(calmidazolium)和STOCK1N-35874(詳細計算分析結果參見https://github.com/yeaouh/antifungal)。
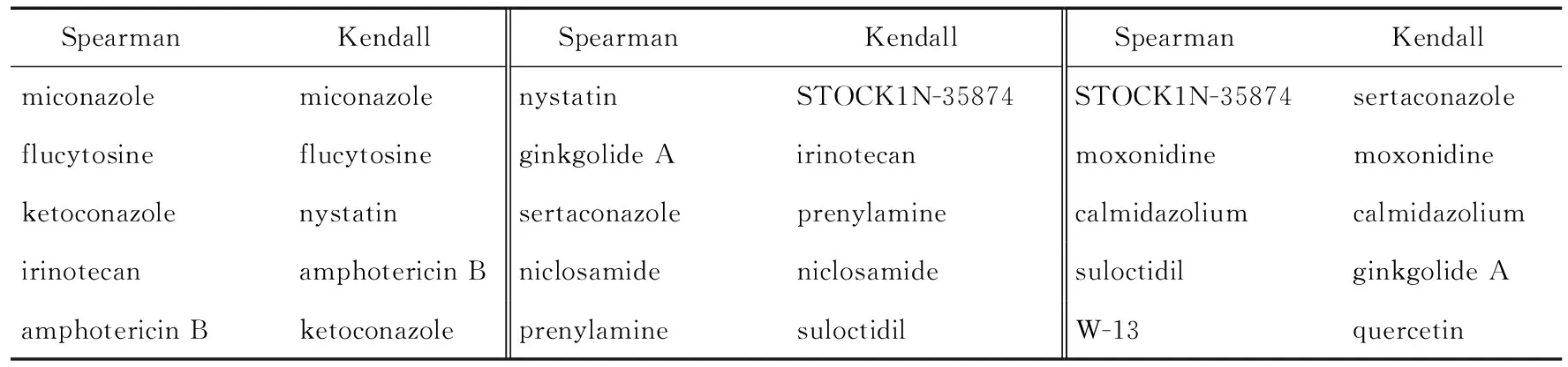
Table 3 Prediction results of antifungal candidates 表3 抗真菌候選藥物預測結果

Figure 2 Convergence results of RankAggreg圖2 RankAggreg收斂結果
本文基于WTCS、GSEA算法以及所設計的藥物發現分析方法對5種具有代表性的抗真菌藥物進行了相似藥物預測,并通過綜合排序得到了抗真菌藥物最相似藥物列表,最高相似度為88%,得到的抗真菌相似藥物列表具有一定的參考價值。在最終計算得到的抗真菌藥物預測結果中,經過文獻查證,已經證明舍他康唑[27]、舒洛地爾[28]能夠應用于臨床抗真菌藥物治療。另外,根據文獻顯示,一些抗氧化(如槲皮素)、抗癌(如伊利替康、槲皮素)等藥物的作用機理可能同樣適用于真菌[1],從而達到治療真菌感染的目的,但這些猜測顯然需要實驗研究進行確認。
利用高通量組學數據對現有藥物進行篩選分析能夠大大縮短藥物發現流程。通過計算得到的理論結果有待進一步的細胞、動物及臨床實驗驗證。下一步將基于更大規模的數據集進行探索,尋找使得預測結果更加可靠的方法,以及探索深度學習技術在組學數據分析處理、藥物設計發現中的應用,實現更為精準的抗真菌藥物預測發現。
猜你喜歡列表相似性排序一類上三角算子矩陣的相似性與酉相似性數學物理學報(2022年5期)2022-10-09排序不等式中學生數理化·七年級數學人教版(2022年11期)2022-02-14學習運用列表法小學生學習指導(中年級)(2021年4期)2021-04-27淺析當代中西方繪畫的相似性河北畫報(2020年8期)2020-10-27擴列吧課堂內外(初中版)(2020年5期)2020-06-19恐怖排序科普童話·學霸日記(2020年1期)2020-05-08節日排序小天使·一年級語數英綜合(2019年2期)2019-01-10低滲透黏土中氯離子彌散作用離心模擬相似性浙江大學學報(工學版)(2016年2期)2016-06-05列表畫樹狀圖各有所長中學生數理化·中考版(2015年10期)2015-09-10不含3-圈的1-平面圖的列表邊染色與列表全染色華東師范大學學報(自然科學版)(2014年3期)2014-03-11